抓取豆瓣书单并存到Notion里面 在notion开放Notion API 之后,一直在思考对于我能够有什么应用场景。主要思考的有几个方向。
建立一个读书清单并且具有相应的图书封面以及读书感受
针对一些循环任务可以使用程序自动来设定,而不是要重复建立
所以第一个任务是读书清单的建立。目前在读的一些书,如果要找到完整的信息,在豆瓣读书里比较容易获得。所以我的想法是,使用爬虫抓取豆瓣里的个人书单信息。然后将这些重要信息按照notion的格式要求,透过API更新到Notion里面。具体成品参考Notion书单
使用python抓取豆瓣书单 本次没有使用之前的requests包去抓取资料,而是使用requests_html去进行获取Html内容并进行数据解析。
requests-html 具有以下特性
完全支持 JavaScript
CSS 选择器
XPath 选择器
模拟用户代理(如同真正的网络浏览器)
自动跟踪重定向连接池
cookie 持久化
使用 pip install requests-html进行安装。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 from requests_html import HTMLSessionsession=HTMLSession() headers={ 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36' , 'Cookie' : '' } url='https://book.douban.com/people/45774109/collect' data=session.get(url=url,headers=headers) booklist=data.html.xpath('//li[@class="subject-item"]' ) for book in booklist: bookname=book.xpath('//h2/a/@title' )[0 ] print (bookname) picurl=book.xpath('//img/@src' )[0 ] author=book.xpath('//div[@class="pub"]' )[0 ].text.split('/' )[0 ] finishdate=book.xpath('//span[@class="date"]' )[0 ].text.split(' ' )[0 ] status=book.xpath('//span[@class="date"]' )[0 ].text.split(' ' )[1 ] createdoubanpage(bookname,author,finishdate,picurl,status)
使用Notion API 存储数据 Notion目前在官网上的介绍是使用js方法和curl命令来进行数据交互。所以熟悉JS的可以直接使用。而我在学习Python的使用。在网上已经有大神已经封装了这些接口和方法。推荐使用 Notion-Client 包来进行数据传输。使用命令pip install notion-client 进行安装。请注意该包仅适用于python为3.7以上。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 from notion_client import Clientfrom requests_html import HTMLSessiondef createdoubanpage (book,author,finishdate,picurl,status ): notion = Client(auth="secret_XXXXXXX" ) database_id= "31fd2XXXXXXXXXX" newaddbook=0 new_page ={ 'Book' : {'id' : 'title' , 'title' : [{ 'text' : {'content' : book, 'link' : None }, 'type' : 'text' }], 'type' : 'title' }, '作者' : { 'rich_text' : [{ 'text' : {'content' : author, 'link' : None }, 'type' : 'text' }], 'type' : 'rich_text' }, '完成日期' : {'date' : {'end' : None , 'start' : finishdate}, 'type' : 'date' }, '状态' : { 'select' : {'name' : status}, 'type' : 'select' }} new_child= [ { 'type' : 'image' , 'image' : { 'external' : {'url' : picurl}, 'type' : 'external' , }, } ] results = notion.databases.query( **{ "database_id" : database_id, "filter" : {"property" : "Book" , "text" : {"contains" : book}}, } ).get("results" ) print (results) if len (results)==0 : newres=notion.pages.create(parent={"database_id" : database_id}, properties=new_page,children=new_child) print (f"create page {book} ok" ) newaddbook=newaddbook+1 else : print (f"Have the page {book} ,no need create" ) return newaddbook
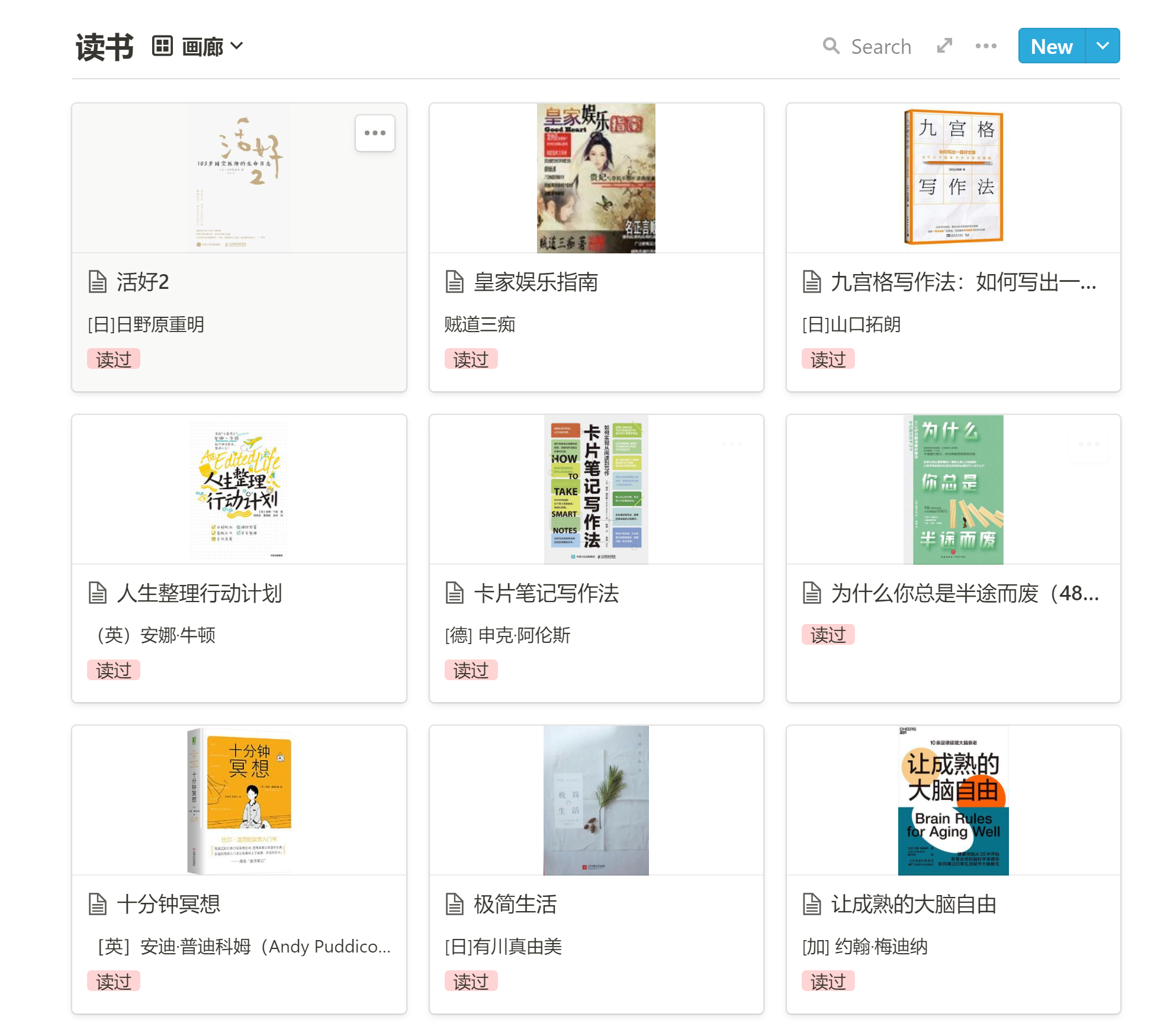
在Notion的页面范例页面 设置好格式,然后数据传输完成即可生成下面的画廊模式。
下一步的思考 本来计划将此任务部署在个人服务器上面或者腾讯云函数。在测试时发现Notion API增加数据校验,对于图片格式有异常抛出。所以暂时部署任务失败。
2021/08/25 目前官网 上最新介绍又支持img类型了。所以可以继续部署了
Only text-like and media-like blocks are currently available At present the API only supports text-like and media-like block types which are listed in the reference below. All other block types will continue to appear in the structure, but only contain a type set to "unsupported".
1 2 3 4 5 6 7 8 9 10 { "type" : "image" , "image" : { "type" : "external" , "external" : { "url" : "https://website.domain/images/image.png" } } }