机器学习-1
机器学习
机器学习是让计算机无须进行明确编程就具备学习能力。
机器学习和传统编程有什么区别呢?简单的两个图来理解:
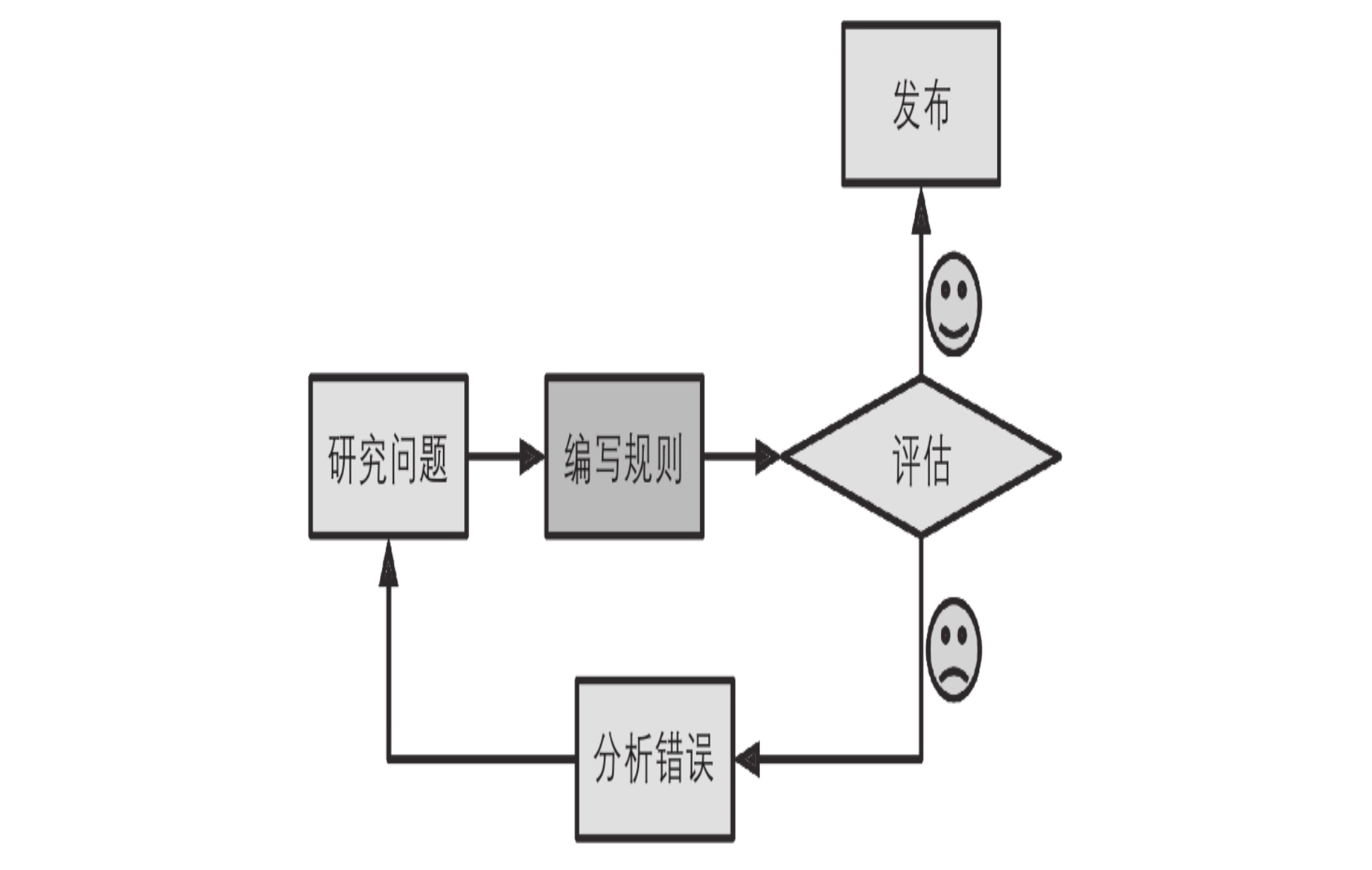
- 下图就是正常的编程逻辑,发现一个问题,编写规则来处理。如果发现规则有缺失,就去补充这个逻辑。
- 机器学习,则是在未知规则的条件下,让机器自动发现并实现算法。可以简单理解为一个黑盒子。我们并不清楚最后如何实现。
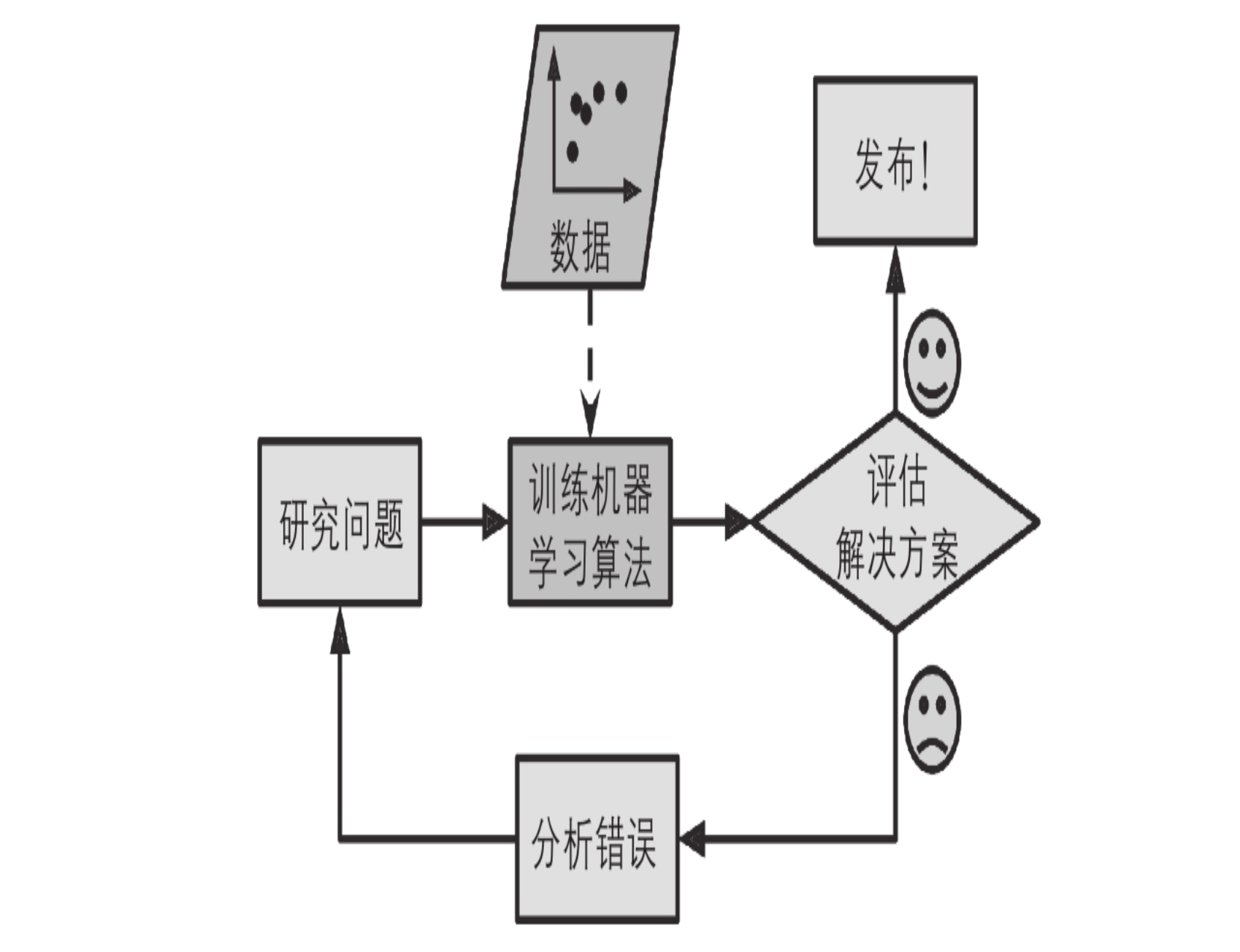
机器学习的另一个亮点是善于处理对于传统方法而言太复杂或没有已知算法的问题
使用机器学习方法挖掘大量数据来帮助发现不太明显的规律。这称作数据挖掘
有监督学习与无监督学习
有监督学习
在有监督学习中,提供给算法的包含所需解决方案的训练集称为标签。分类任务是一个典型的有监督学习任务。垃圾邮件过滤器就是一个很好的示例。常用的算法有:
k-近邻算法
线性回归
逻辑回归
支持向量机(SVM)
决策树
随机森林
神经网络
无监督学习
无监督学习的训练数据都是未经标记的。系统会在没有“老师”的情况下进行学习。常用算法:
聚类算法
k-均值算法
DBSCAN
分层聚类分析(HCA)
异常检测和新颖性检测
单类SVM
孤立森林
可视化和降维
主成分分析(PCA)
核主成分分析
局部线性嵌入(LLE)
t-分布随机近邻嵌入(t-SNE)
关联规则学习
Apriori
Eclat
先使用降维算法减少训练数据的维度,再将其提供给另一个机器学习算法(例如有监督学习算法)。这会使它运行得更快,数据占用的磁盘空间和内存都会更小,在某些情况下,执行性能也会更高。
批量学习与在线学习
看系统是否可以从传入的数据流中进行增量学习
批量学习
在批量学习中,系统无法进行增量学习——即必须使用所有可用数据进行训练。这需要大量时间和计算资源,所以通常都是离线完成的。离线学习就是先训练系统,然后将其投入生产环境,这时学习过程停止,它只是将其所学到的应用出来。
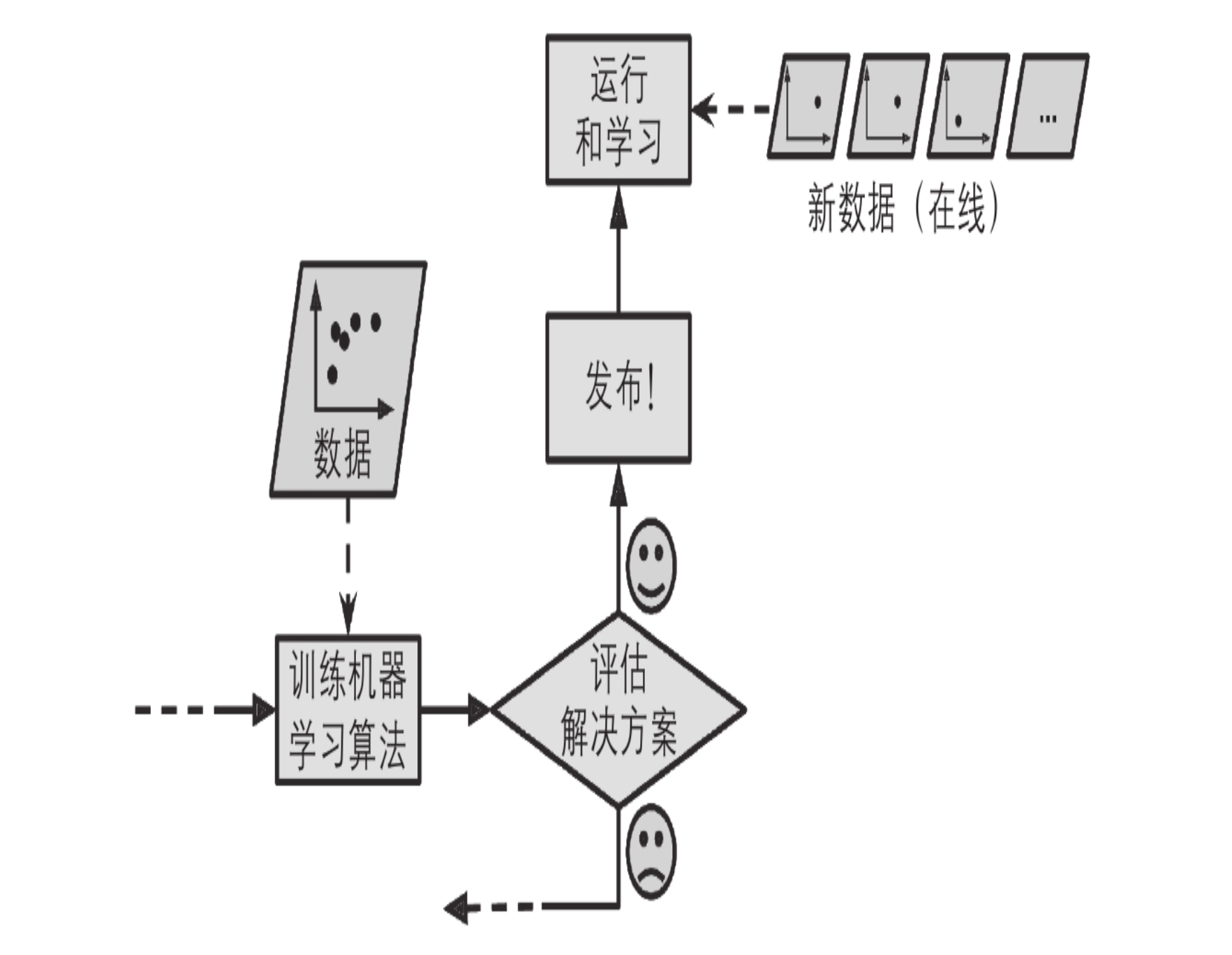
在线学习
在在线学习中,你可以循序渐进地给系统提供训练数据,逐步积累学习成果。
机器学习的步骤
- 研究数据。
- 选择模型。
- 使用训练数据进行训练(即前面学习算法搜索模型参数值,从而使成本函数最小化的过程)
- 最后,应用模型对新示例进行预测(称为推断),希望模型的泛化结果不错。
测试与验证
选择是将数据分割成两部分:训练集和测试集。顾名思义,你可以用训练集的数据来训练模型,然后用测试集的数据来测试模型。应对新场景的误差率称为泛化误差(或者样例外误差)。通常将80%的数据用于训练,而保持20%供测试用。
学习资料来源:

评论
评论插件加载失败
正在加载评论插件